Comparing Obelisk with DBOS
2025-11-26Obelisk and DBOS are both open-source durable workflow engines.
Let's see how they compare in terms of ease of use, nondeterminism prevention and performance.
I will go through the Learn DBOS Java tutorial and compare it with Rust version of the same code written for Obelisk. I chose Java because of familiarity, however the library has just been released so the code is still quite young. On the Obelisk side, Rust is the obvious choice as it has the best performance and tooling.
Setting up the environment
DBOS-Java needs a JDK, Gradle and a PosgreSQL database.
For building WASM Components we need Rust and Cargo.
Intro into deterministic workflow engines
As both Obelisk and DBOS emphasize, workflows must be deterministic and activities / steps must be idempotent.
This ensures that long running workflows can continue after a server crash or when they are migrated from one machine to another.
Activities can be retried automatically on a failure, but even a successful activity might be retried if the server crashes just before persisting the result.
Authoring workflows
Our test bed will be:
- An idempotent activity (step in DBOS lingo) that interacts with the world: sleeps and creates a file
- A
serialandparallelworkflows that run the activity with persistent sleep in a loop - An HTTP endpoint (webhook endpoint in Obelisk lingo) that triggers these workflows.
Skip to Experiments to avoid the wall of code.
DBOS
In the DBOS repository, the step, workflows and a HTTP server can be put into a single Java class:
package com.example;
import java.nio.file.Files;
import java.nio.file.Path;
import java.time.Duration;
import java.util.List;
import java.util.AbstractMap;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.slf4j.LoggerFactory;
import dev.dbos.transact.DBOS;
import dev.dbos.transact.StartWorkflowOptions;
import dev.dbos.transact.config.DBOSConfig;
import dev.dbos.transact.workflow.Queue;
import dev.dbos.transact.workflow.Workflow;
import dev.dbos.transact.workflow.WorkflowHandle;
import io.javalin.Javalin;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
interface Example {
public int serial() throws Exception;
public int childWorkflow(int i) throws Exception;
public long parallelParent() throws Exception;
}
class ExampleImpl implements Example {
private final Queue queue;
private Example proxy;
public ExampleImpl(Queue queue) {
this.queue = queue;
}
public void setProxy(Example proxy) {
this.proxy = proxy;
}
// Idempotent activity
private static int step(int idx, int sleepMillis) throws Exception {
System.out.printf("Step %d started%n", idx);
Thread.sleep(sleepMillis);
System.out.printf("Step %d creating file%n", idx);
Path path = Path.of("file-" + idx + ".txt");
Files.write(path, new byte[0]);
System.out.printf("Step %d completed%n", idx);
return idx;
}
@Workflow(name = "serial")
public int serial() throws Exception {
System.out.println("serial started");
int acc = 0;
for (int i = 0; i < 10; i++) {
System.out.println("Persistent sleep started");
DBOS.sleep(Duration.ofSeconds(1));
System.out.println("Persistent sleep finished");
final int i2 = i;
int result = DBOS.runStep(() -> step(i2, 200 * i2), "step " + i);
acc += result;
System.out.printf("step(%d)=%d%n", i, result);
}
System.out.println("serial completed");
return acc;
}
// This child workflow exists because there is no way to run steps directly in
// parallel.
@Workflow(name = "parallel-child")
public int childWorkflow(int i) throws Exception {
return DBOS.runStep(() -> step(i, 200 * i), "step " + i);
}
@Workflow(name = "parallel-parent")
public long parallelParent() throws Exception {
System.out.println("parallel-parent started");
HashSet<Map.Entry<Integer, WorkflowHandle<Integer, Exception>>> handles = new HashSet<>();
for (int i = 0; i < 10; i++) {
final int index = i;
var handle = DBOS.startWorkflow(
() -> this.proxy.childWorkflow(index),
new StartWorkflowOptions().withQueue(this.queue));
handles.add(new AbstractMap.SimpleEntry<>(i, handle)); // Tuple (i, handle)
}
System.out.println("parallel-parent submitted all parallel-child workflows");
long acc = 0;
for (var entry : handles) {
int result = entry.getValue().getResult();
acc = 10 * acc + result; // Order-sensitive
int i = entry.getKey();
System.out.printf("parallel-child(%d)=%d, acc:%d%n", i, result, acc);
DBOS.sleep(Duration.ofMillis(300));
}
System.out.println("parallel-parent completed");
return acc;
}
}
public class App {
public static void main(String[] args) throws Exception {
Logger root = (Logger) LoggerFactory.getLogger(Logger.ROOT_LOGGER_NAME);
root.setLevel(Level.ERROR);
DBOSConfig config = DBOSConfig.defaults("java1")
// .withConductorKey(System.getenv("CONDUCTOR_KEY"))
.withAppVersion("test-app-version") // Allow changing the code when replaying workflows
.withDatabaseUrl(System.getenv("DBOS_SYSTEM_JDBC_URL"))
.withDbUser(System.getenv("PGUSER"))
.withDbPassword(System.getenv("PGPASSWORD"));
DBOS.configure(config);
Queue queue = new Queue("example-queue");
DBOS.registerQueue(queue);
ExampleImpl impl = new ExampleImpl(queue);
Example proxy = DBOS.registerWorkflows(Example.class, impl);
impl.setProxy(proxy);
DBOS.launch();
Javalin.create()
.get("/serial", ctx -> {
int acc = proxy.serial();
ctx.result("serial workflow completed: " + acc);
})
.get("/parallel", ctx -> {
long acc = proxy.parallelParent();
ctx.result("parallel workflow completed: " + acc);
})
.start(9000);
}
}Obelisk
Each component in the repository is a separate Cargo package. Obelisk also requires defining a schema between components using WIT (WebAssembly Interface Type) IDL.
Activity
package tutorial:activity;
interface activity-sleepy {
step: func(idx: u64, sleep-millis: u64) -> result<u64>;
}
world any {
export tutorial:activity/activity-sleepy;
}use exports::tutorial::activity::activity_sleepy::Guest;
use std::time::Duration;
use wit_bindgen::generate;
generate!({ generate_all });
struct Component;
export!(Component);
impl Guest for Component {
fn step(idx: u64, sleep_millis: u64) -> Result<u64, ()> {
println!("Step {idx} started");
std::thread::sleep(Duration::from_millis(sleep_millis));
println!("Step {idx} creating file");
let path = format!("file-{idx}.txt");
std::fs::File::create(path)
.inspect_err(|err| eprintln!("{err:?}"))
.map_err(|_| ())?;
println!("Step {idx} completed");
Ok(idx)
}
}Workflow
package tutorial:workflow;
interface workflow {
serial: func() -> result<u64>;
parallel: func() -> result<u64>;
}
world any {
export tutorial:workflow/workflow;
// Import of the activity.
import tutorial:activity/activity-sleepy;
// Generated extensions for `parallel` workflow.
import tutorial:activity-obelisk-ext/activity-sleepy;
// Obelisk SDK
import obelisk:types/execution@3.0.0;
import obelisk:workflow/workflow-support@3.0.0;
import obelisk:log/log@1.0.0;
}use exports::tutorial::workflow::workflow::Guest;
use obelisk::{
log::log,
types::time::{Duration, ScheduleAt},
workflow::workflow_support::{self, ClosingStrategy, new_join_set_generated},
};
use std::collections::HashSet;
use tutorial::{
activity::activity_sleepy::step,
activity_obelisk_ext::activity_sleepy::{step_await_next, step_submit},
};
use wit_bindgen::generate;
mod util;
generate!({ generate_all });
struct Component;
export!(Component);
impl Guest for Component {
fn serial() -> Result<u64, ()> {
log::info("serial started");
let mut acc = 0;
for i in 0..10 {
log::info("Persistent sleep started");
workflow_support::sleep(ScheduleAt::In(Duration::Seconds(1)));
log::info("Persistent sleep finished");
let result = step(i, i * 200).inspect_err(|_| log::error("step timed out"))?;
acc += result;
log::info(&format!("step({i})={result}"));
}
log::info("serial completed");
Ok(acc)
}
#[allow(clippy::mutable_key_type)]
fn parallel() -> Result<u64, ()> {
log::info("parallel started");
let max_iterations = 10;
let mut handles = HashSet::new();
for i in 0..max_iterations {
let join_set = new_join_set_generated(ClosingStrategy::Complete);
step_submit(&join_set, i, i * 200);
handles.insert((i, join_set));
}
log::info("parallel submitted all child executions");
let mut acc = 0;
for (i, join_set) in handles {
let (_execution_id, result) =
step_await_next(&join_set).expect("every join set has 1 execution");
let result = result.inspect_err(|_| log::error("step timed out"))?;
acc = 10 * acc + result; // order-sensitive
log::info(&format!("step({i})={result}, acc={acc}"));
workflow_support::sleep(ScheduleAt::In(Duration::Milliseconds(300)));
}
log::info(&format!("parallel completed: {acc}"));
Ok(acc)
}
}Webhook endpoint
package any:any;
world any {
import tutorial:workflow/workflow;
}use crate::tutorial::workflow::workflow;
use anyhow::Result;
use wit_bindgen::generate;
use wstd::http::body::Body;
use wstd::http::{Error, Request, Response, StatusCode};
generate!({ generate_all });
#[wstd::http_server]
async fn main(request: Request<Body>) -> Result<Response<Body>, Error> {
let path = request.uri().path_and_query().unwrap().as_str();
let response = match path {
"/serial" => {
let acc = workflow::serial().unwrap();
Response::builder().body(Body::from(format!("serial workflow completed: {acc}")))
}
"/parallel" => {
let acc = workflow::parallel().unwrap();
Response::builder().body(Body::from(format!("parallel workflow completed: {acc}")))
}
_ => Response::builder()
.status(StatusCode::NOT_FOUND)
.body(Body::from("not found")),
}
.unwrap();
Ok(response)
}Ergonomics
DBOS uses a callback approach when submitting child executions:
int result = DBOS.runStep(() -> step(i, 200 * i), "step " + i);The drawback here is lower readability when orchestrating a large number of steps. DBOS could use Proxy pattern instead, but it would make more difficult to attach metadata such as name, retry configuration etc.
Obelisk workflows can call a child execution directly without a callback:
let result = step(i, i * 200).unwrap();or using Extension Functions, automatically generated from the activity's WIT file:
step_submit(&join_set, i, i * 200);
let (_execution_id, result) = step_await_next(&join_set).unwrap();The great thing about DBOS is that the whole thing fits into a single Java file.
However, schema-first approach has several advantages:
- Strong, explicit interface contracts
- No way of forgetting to use the callback style or to construct a proxy object. This would lead to mixing side effects into workflows.
- Cross-language interoperability: The WASM Component Model supports many languages such as Rust, JavaScript, Python, Go and more.
- Versioning and backward-compatibility: Activities can export several versions of the same interface, enabling workflows to catch up on their pace.
- Codegen allows creating multiple variants of the same exported function, taking advangates of both proxy and callback patterns without the drawbacks.
Experiments
Experiment A: Simulating a server crash
The task is to start the workflow, kill the server and start it again to see if the workflow finishes.
Submitting the parallel workflow in DBOS and then killing the server revealed an unplesent surprise:
After restart the workflow ended in ERROR state, with an error and a huge stack trace:
11:02:54.411 [pool-1-thread-2] ERROR dev.dbos.transact.execution.DBOSExecutor -- enqueueWorkflow
dev.dbos.transact.exceptions.DBOSWorkflowExecutionConflictException: Conflicting workflow ID 66b7739d-0d83-4b02-b99c-e824c6e2bfd5
...However, after I reported the bug, the PR was merged within 24 hours. Kudos to the DBOS team.
Other than that, the only notable issue I found was that DBOS recovery started after around a one minute delay. I was instructed to disable Conductor, a proprietary distributed orchestrator, which resolved the problem.
No problems with Obelisk were found.
Experiment B: Breaking determinism with code changes
Changing code of a running workflow is a delicate process. It can only work when the change does not affect the execution log, or when the running execution did not reach the changed line yet.
One clever trick that DBOS does is that it detects code changes by hashing the bytecode of workflow classes. Obviously this is a best-effort solution, as the change can come from a dependency, or from using a nondeterministic construct, as discussed later. Instead of extracting the workflow logic into another file, I have disabled the hashing by setting a constant application version.
Obelisk does not currently perform a hash digest of the workflow's WASM executable. In the future, it will store the WASM hash when an execution is created. Contrary to DBOS, this approach reliably reflects whether the code (including dependencies) changed or not.
DBOS should throw an error when events produced on replay do not match the original execution log.
Let's start with an obvious change in the serial workflow:
public int serial() throws Exception {
...
- for (int i = 0; i < 10; i++) {
+ for (int i = 9; i >= 0; i--) {
// Note that the step name changed as well:
int result = DBOS.runStep(() -> step(i2, 200 * i2), "step " + i); fn serial() -> Result<(), ()> {
...
- for i in 0..10 {
+ for i in (0..10).rev() {
// Call the activity with different parameters
let result = step(i, i * 200).unwrap();An in-progresss execution that is replayed after restart should detect it immediately as the i
variable is used as a parameter to step invocation.
Both engines detect the failure: 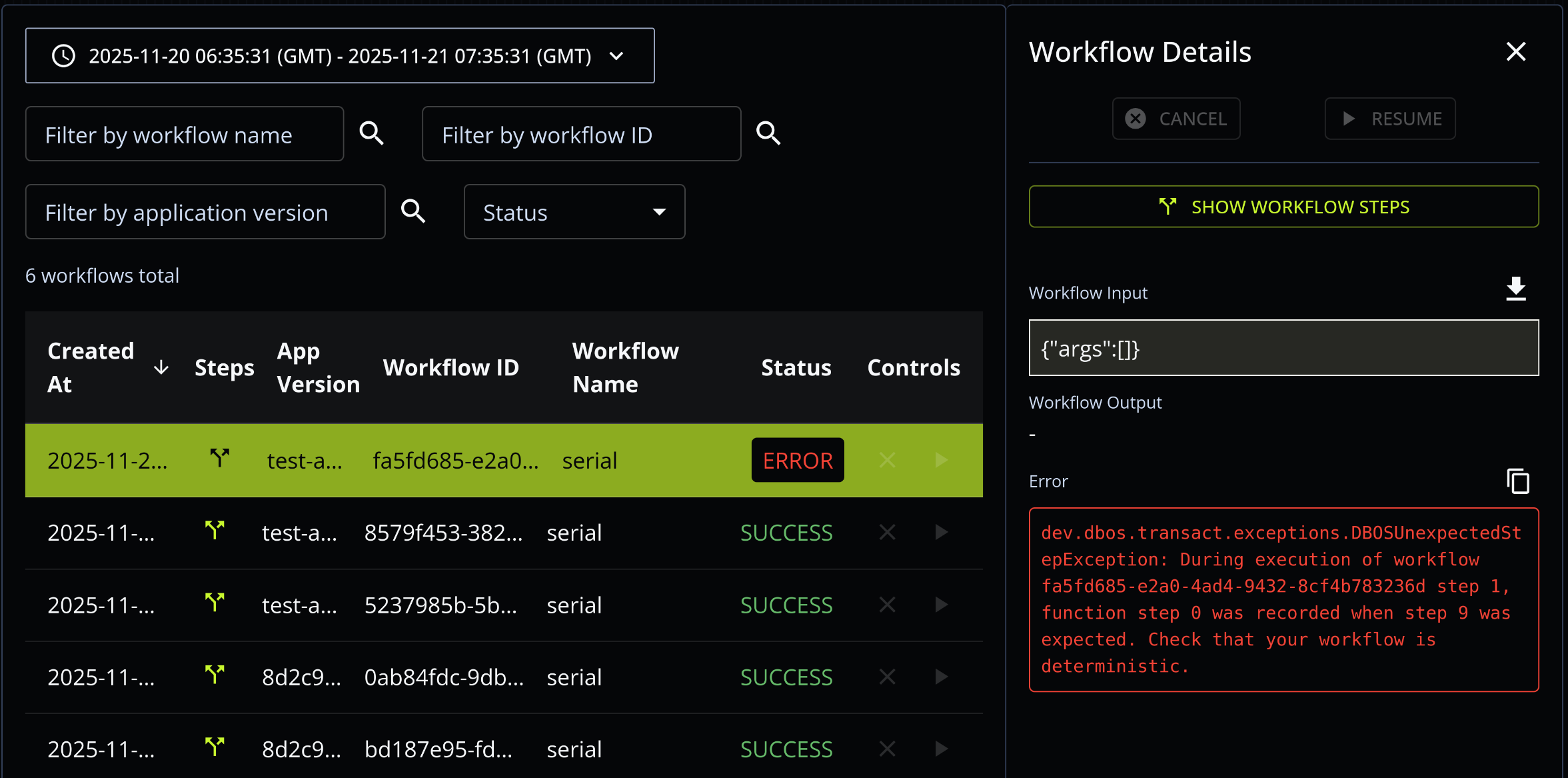
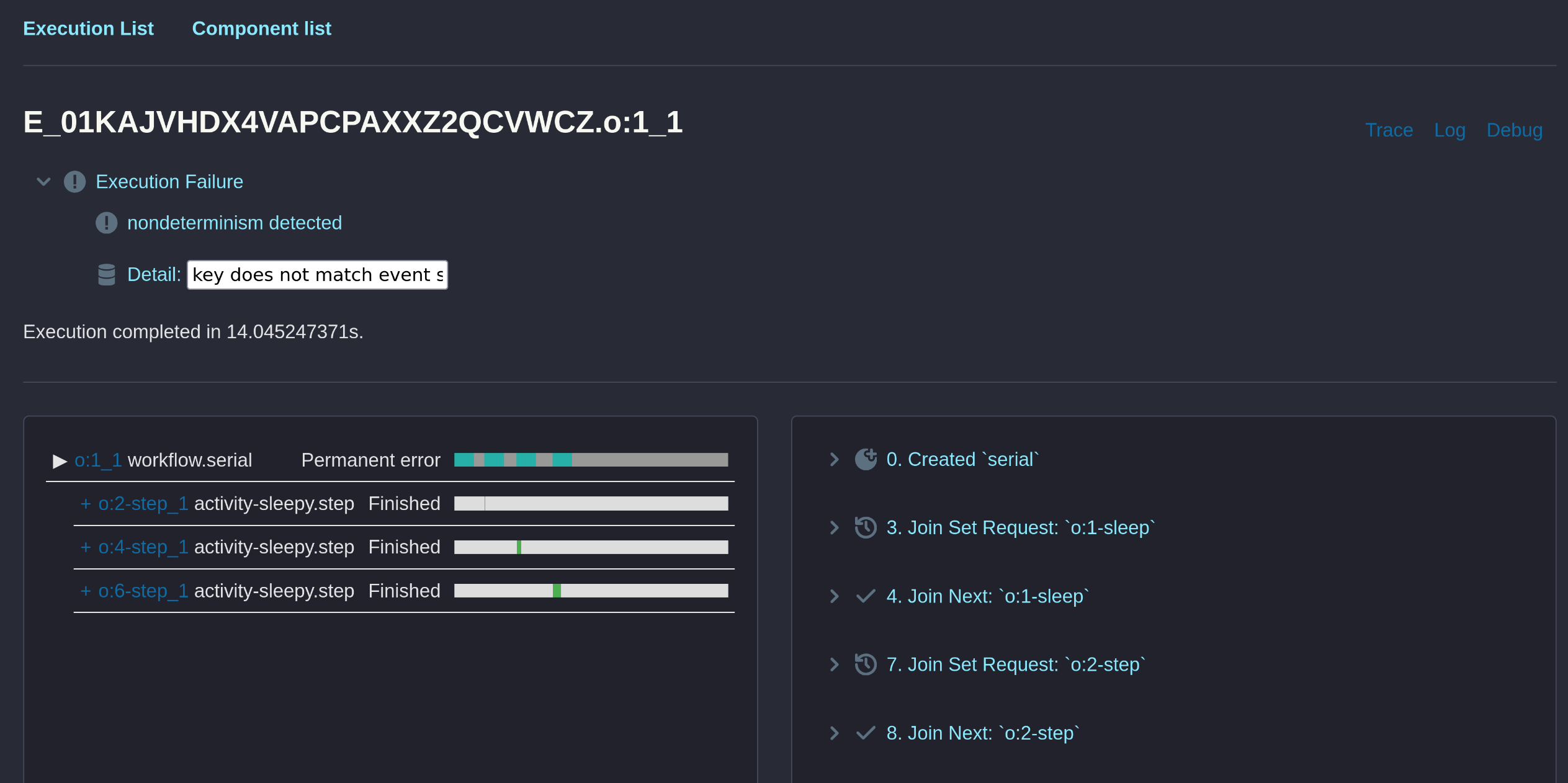
Full error:
key does not match event stored at index 4:
key: ChildExecutionRequest(E_01KAJVHDX4VAPCPAXXZ2QCVWCZ.o:1_1.o:2-step_1, tutorial:activity/activity-sleepy.step, params: [9, 1800]),
event: JoinSetRequest(ChildExecutionRequest(E_01KAJVHDX4VAPCPAXXZ2QCVWCZ.o:1_1.o:2-step_1, tutorial:activity/activity-sleepy.step, params: [0, 0]))Notice that the DBOS error only contains the naming differences, step 0 vs step 9 whereas
Obelisk contains the actual parameters. In fact, if we are a bit lazy, and do not serialize
parameters into the name properly:
- int result = DBOS.runStep(() -> step(i2, 200 * i2), "step " + i);
+ int result = DBOS.runStep(() -> step(i2, 200 * i2), "step");the workflow will finish happily with result 0+1+2+6+5+4+3+2+1+0=24!
Experiment C: Trimming execution events
Another interesting test is to lower the number of iterations. Let's start a serial workflow, wait
until around step 8, kill the server and change:
public void serial() throws Exception {
...
- for (int i = 0; i < 10; i++) {
+ for (int i = 0; i < 3; i++) {
...
int result = DBOS.runStep(() -> step(i2, 200 * i2), "step " + i);This kind of error can lead to resources like temporary VMs running without a cleanup and should be reported by the engine.
The latest version of Obelisk detects it correctly:
found unprocessed event stored at index 18: event: JoinSetCreate(o:7-sleep)DBOS marks the trimmed execution as successful, returning 0+1+2=3.
Full disclosure: Obelisk 0.26.2 did not detect these changes correctly, fixes landed for 0.27.0 .
Experiment D: Breaking determinism using nondeterministic code
Instead of changing the code, determinism can be broken by using nondeterministic constructs. DBOS documentation warns:
Java's threading and concurrency APIs are non-deterministic. You should use them only inside steps.
Using any source of nondeterminism, including current date, IO, environment variables, RNG or something more subtle like hash maps will break the replay as well.
For posterity, let's replace the ArrayList / Vec with a hash set:
@Workflow(name = "parallel-parent")
public long parallelParent() throws Exception {
System.out.println("parallel-parent started");
- ArrayList<Map.Entry<Integer, WorkflowHandle<Integer, Exception>>> handles = new ArrayList<>();
+ HashSet<Map.Entry<Integer, WorkflowHandle<Integer, Exception>>> handles = new HashSet<>();
for (int i = 0; i < 10; i++) {
final int index = i;
var handle = DBOS.startWorkflow(
() -> this.proxy.childWorkflow(index),
new StartWorkflowOptions().withQueue(this.queue));
handles.add(new AbstractMap.SimpleEntry<>(i, handle)); // Tuple (i, handle)
}
System.out.println("parallel-parent submitted all parallel-child workflows");
long acc = 0;
for (var entry : handles) {
int result = entry.getValue().getResult();
acc = 10 * acc + result; // Order-sensitive
int i = entry.getKey();
System.out.printf("parallel-child(%d)=%d, acc:%d%n", i, result, acc);
DBOS.sleep(Duration.ofMillis(300));
}
System.out.println("parallel-parent completed");
return acc;
}Crasing an in-progress workflow and replaying it in a new process:
parallel-parent started
parallel-parent submitted all parallel-child workflows
parallel-child(2)=2, acc:2
parallel-child(8)=6, acc:26
parallel-child(5)=8, acc:268
parallel-child(3)=5, acc:2685
parallel-child(4)=4, acc:26854
parallel-child(7)=9, acc:268549
parallel-child(1)=7, acc:2685497
parallel-child(9)=0, acc:26854970
# replayed up to this point
parallel-child(0)=0, acc:268549700
parallel-child(6)=6, acc:2685497006
parallel-parent completed: 2685497006Noticed something is off? parallel-child(n) should always return n, and the final acc should
contain every digit exactly once. However the ordering of HashSet iteration depends on each
object’s memory address or a per-run JVM-specific identity value. This is an obvious source of
nondeterminism, and in this case leads to replaying wrong return values, exactly as in Experiment B.
The best DBOS could do here is to throw a nondeterminism detected error.
Applying the same change in Obelisk:
fn parallel() -> Result<u64, ()> {
log::info("parallel started");
let max_iterations = 10;
- let mut handles = Vec::new();
+ let mut handles = HashSet::new();
for i in 0..max_iterations {
let join_set = new_join_set_generated(ClosingStrategy::Complete);
step_submit(&join_set, i, i * 200);
handles.insert((i, join_set));
}
log::info("parallel submitted all child executions");
let mut acc = 0;
for (i, join_set) in handles {
let (_execution_id, result) =
step_await_next(&join_set).expect("every join set has 1 execution");
let result = result.inspect_err(|_| log::error("step timed out"))?;
acc = 10 * acc + result; // order-sensitive
log::info(&format!("step({i})={result}, acc={acc}"));
workflow_support::sleep(ScheduleAt::In(Duration::Milliseconds(300)));
}
log::info(&format!("parallel completed: {acc}"));
Ok(acc)
}I have crashed an execution twice, but its output is stable:
TRACE (replay) parallel started
TRACE (replay) parallel submitted all child executions
TRACE (replay) step(2)=2, acc=2
TRACE (replay) step(1)=1, acc=21
TRACE (replay) step(3)=3, acc=213
TRACE (replay) step(5)=5, acc=2135
TRACE (replay) step(0)=0, acc=21350
TRACE (replay) step(9)=9, acc=213509
TRACE (replay) step(4)=4, acc=2135094
TRACE (replay) step(7)=7, acc=21350947
TRACE (replay) step(8)=8, acc=213509478
INFO step(6)=6, acc=2135094786
INFO parallel completed: 2135094786I am not aware of any way how to inject nondeterminism into the code: Accessing IO, source of randomness, spawning a thread etc, are all forbidden and lead to WASM trap (a non-recoverable runtime fault). Even if there was a way to bypass the WASM sandbox, it would only lead to the same result as we saw earlier with code changes - a nondeterminism detected error.
This experiment shows that without a properly isolated environment code that works fine on the first run can be utterly broken on replay.
Experiment E: Resource usage with 10k or 100k of workflows
One of main selling points of workflow engines is the fact that the workflows can durably sleep for weeks or more.
Let's model the situation where a main workflow spawns one child workflow for every customer. This child workflow will just sleep for 1 day in order to drive some business logic.
@Workflow
public void sleepyWorkflow(int idx) {
System.out.printf("%d%n", idx);
DBOS.sleep(Duration.ofDays(1));
// do some logic here
}
// Test submitting many customer workflows
@Workflow
public void sleepyParent(int max) {
var handles = new ArrayList<WorkflowHandle<Void, RuntimeException>>();
for (int i = 0; i < max; i++) {
final int index = i;
System.out.printf("Submitting child workflow %d%n", i);
var handle = DBOS.startWorkflow(
() -> this.proxy.sleepyWorkflow(index),
new StartWorkflowOptions().withQueue(this.queue));
handles.add(handle);
}
System.out.printf("Created %s child workflows%n", max);
int counter = 0;
for (var handle : handles) {
handle.getResult();
counter++;
System.out.printf("Collected %d child workflows%n", counter);
}
System.out.printf("Done waiting for %d child workflows%n", max);
}When executing the parent workflow submitting 10k child workflows (on a machine wih 16GB of RAM), the JVM process was slowing down until it reached a breaking point. After a few minutes, with parent workflow reporting the index 8602, the process RSS grew from ~130MB to 1.3GB, reported an OOM error and did not make any further progress. Even after restart the same thing happened:
[172,701s][warning][os,thread] Failed to start thread "Unknown thread" - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 0k, detached.
[172,701s][warning][os,thread] Failed to start the native thread for java.lang.Thread "pool-1-thread-18613"
Exception in thread "QueuesPollThread" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reachedThis could be mitigated by changing the limits on the OS level, but using one thread for each inactive workflow execution seems excessive.
Let's see how Obelisk handles it.
First we create a new workflow component:
package tutorial:sleepy;
interface sleepy-workflow {
sleepy-workflow: func(idx: u64) -> result;
}impl exports::tutorial::sleepy::sleepy_workflow::Guest for Component {
fn sleepy_workflow(idx: u64) -> Result<(), ()> {
log::info(&idx.to_string());
workflow_support::sleep(ScheduleAt::In(Duration::Days(1)));
// do some logic here
Ok(())
}
}Then we generate the extension WIT file and import it to the tutorial workflow component.
package tutorial:workflow;
interface workflow {
serial: func() -> result<u64>;
parallel: func() -> result<u64>;
+ sleepy-parent: func(max: u64) -> result;
}
world any {
export tutorial:workflow/workflow;
+ import tutorial:sleepy-obelisk-ext/sleepy-workflow;
fn sleepy_parent(max: u64) -> Result<(), ()> {
let join_set = &new_join_set_generated(ClosingStrategy::Complete);
for idx in 0..max {
log::info(&format!("Submitting child workflow {idx}"));
sleepy_workflow_submit(join_set, idx);
}
log::info(&format!("Created {max} child workflows"));
for counter in 0..max {
let (_execution_id, _result) = sleepy_workflow_await_next(join_set).unwrap();
log::debug(&format!("Collected {counter} child workflows"));
}
log::info(&format!("Done waiting for {max} child workflows"));
Ok(())
}To make it a bit more challenging let's use 100k child workflows. Although Obelisk is yet not hardened for such scale, it managed to start all child workflows with RSS under 500MB. Part of the reason is that instead of using native threads, each execution lives inside a light-weight Tokio task. Inactive workflows are automatically unloaded from memory after a configurable time, which keeps the memory footprint low.
Conclusion
Differences between DBOS and Obelisk can be summarized in a table.
| Feature / Category | DBOS | Obelisk |
|---|---|---|
| Compared Language | Java (Other languages: Python,TypeScript,Go are supported through their respective SDKs). | Rust (Other languages supporting WASM Components: JavaScript, Python, Go) |
| Workflow Definition | Code-first: Workflows and steps can reside in a single Java class. | Schema-first: Uses WIT (WebAssembly Interface Type) IDL to define contracts between components. |
| Ergonomics | Uses a callback approach for steps (e.g., DBOS.runStep(...)), which can lower readability. | Supports direct function calls or generated extension functions, offering cleaner syntax (e.g., step(...)). |
| Determinism Enforcement | Manual/Cooperative: Developers must avoid Java's non-deterministic APIs (threading, IO). Constructs like HashSet can break replay. | Strict/Sandboxed: WASM sandbox prevents access to non-deterministic resources (IO, RNG). HashSet iteration is stable. |
| Nondeterminism Detection | Best-effort: Hashes bytecode of a class, but not the entire codebase. Cannot serialize and compare parameters; marked trimmed workflows as successful. | Strict: reliably detects parameter mismatches and unprocessed events (e.g., trimmed events) on replay. Currently does not hash WASM files. |
| Execution Model | Thread-based: Uses native threads for workflow executions. | Async/Task-based: Uses lightweight Tokio tasks. |
| Scalability & Resource Usage | Lower Scalability: Failed at 10k concurrent workflows (OOM, 1.3GB RSS) due to thread exhaustion. | High Scalability: Successfully handled 100k concurrent workflows (<500MB RSS) by unloading inactive workflows. |
| Infrastructure Dependencies | Requires PostgreSQL. | Embeds SQLite. |
| Web UI | Proprietary, runs in the cloud | Open source, hosted by Obelisk binary |
DBOS is an interesting project that is very easy to start with, as it encourages developers to include it as a library in their main application. This architectural decision shapes its features.
Since there is no isolation, determinism is managed by developer's discipline. This may make it harder to review changes, as seemingly unrelated code changes can lead to (silent) determinism breakage.
Its code change detection can be improved, however it is simply impossible to prevent accidental nondeterminisic constructs unless workflows are completely isolated in a runtime that is built around deterministic execution.
On the plus side, DBOS requires no configuration, as workflows, steps and HTTP endpoints are just code.
Obelisk's main strenth is its WASM runtime:
- no footguns (threads, IO, hash maps etc.) in workflows
- WASM contains the entire code, so associating executions with is original codebase is trivial (although not implemented yet). - See update below.
- Able to unloaded running executions from memory transparently.
- Separation of components
- Coordination through WIT schemas
- Easy to deploy on lightweight VM
Update: Version 0.30.0 stores sha256sum of each WASM component. Executors can be configured to
only lock executions with a matching digest.